SPRUCE 1.0 is out
We are inaugurating this new version of the DigitalPebble blog with an exciting announcement: SPRUCE 1.0 is out — a milestone that marks the project’s transition from early-access versioning to a stable, production-ready, future-proof tool.
SPRUCE is an open-source GreenOps platform that enriches AWS Cost & Usage Reports (CUR) with carbon footprint and energy consumption data. It runs as an Apache Spark job and produces Parquet output ready for querying with DuckDB, Athena, or any Spark-compatible tool. Results can be explored through an interactive Streamlit dashboard or exported as static reports.
Apart from the usual dependency upgrades, here is what changed since 0.10.
Carbon intensity: Ember replaces ElectricityMaps
The carbon intensity module has been replaced. SPRUCE previously used ElectricityMaps average 2024 data (bundled as a large JSON dataset) to look up grid carbon intensity by region. In 1.0, that module and its data files are gone. In their place, a new ember.AverageCarbonIntensity module reads from a curated CSV derived from Ember’s open electricity data.
The main reason behind this change is that ElectricityMaps have stopped sharing their datasets publicly. The methodology is slightly different as Electricity Maps dataset was based on lifecycle, which includes upstream supply-chain emissions (fuel extraction, transport, plant construction). Ember’s CO2 intensity variable is power-sector direct/operational only. Lifecycle values are typically higher than operational for the same grid.
The mapping from cloud region to geolocation has been made possible by the dataset published in Cloud Infrastructure Map.
Scripts to regenerate the data from upstream Ember and Cloud Infrastructure Map sources are included in scripts/, so that the data processing pipeline is verifiable and reproducible.
Multi-provider foundations
SPRUCE 1.0 lays the groundwork for supporting multiple cloud providers beyond AWS. Two significant refactors underpin this:
Boavizta module split into provider-neutral and AWS-specific layers. The former monolithic BoaviztAPI and BoaviztAPIstatic classes have been decomposed into:
AbstractBoaviztaModule— provider-neutral base (column definitions, unknown-instance cache, impact calculation template)AbstractBoaviztaAws— AWS-specific extraction logic for EC2, RDS, and Elasticsearchboavizta.aws.BoaviztAPI/boavizta.aws.BoaviztAPIstatic— concrete AWS variants, now significantly slimmer
This architecture makes it straightforward to add a Google Cloud or Azure Boavizta module by extending AbstractBoaviztaModule without touching the AWS logic.
AWS-specific CCF and networking modules moved to provider-scoped packages. Modules that are inherently AWS-specific (Networking, Serverless, Storage, Accelerators) have been moved under modules/aws/ and modules/ccf/aws/. The shared modules/ root is now reserved for provider-neutral modules.
Bedrock / EcoLogits improvements
The BedrockEcoLogits module — which estimates energy and emissions for Amazon Bedrock LLM inference calls — received two notable fixes:
- Output-tokens-only billing. Bedrock charges for output tokens only (not input tokens). The module now correctly applies inference energy calculations to output token counts alone, matching the EcoLogits methodology more accurately.
- Improved model mapping. The mapping between the values found in the reports and the Ecologits models has been decoupled, which will facilitate use with other formats. The models data are generated automatically from the Ecologits API.
Streamlit dashboard
A new reporting/dashboard.py provides an interactive Streamlit dashboard for exploring SPRUCE output.
- Plotly charts for interactive visualisation of emissions by service, region, and time period
- Metric cards showing total emissions, energy consumption, and cost alongside environmental figures
- Custom CSS theming consistent with SPRUCE’s visual identity
- Filters for billing period, service, and region
- Improved table rendering for detailed drill-down
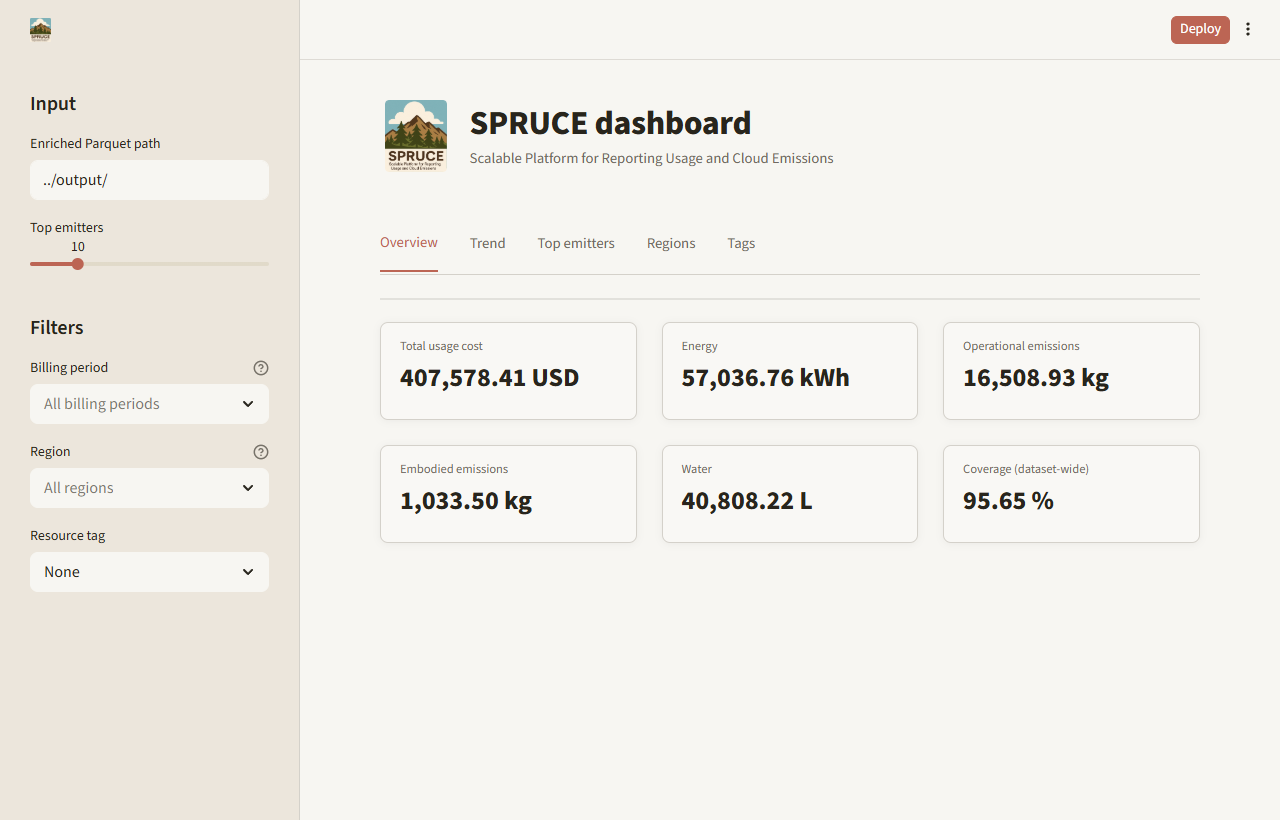
The dashboard is documented in the dashboard how-to. It complements the static reports generated by the script reporting/report.py.
Maven artefacts published to GitHub Packages
SPRUCE JARs are now automatically published to GitHub Packages on each release. This means you can depend on SPRUCE as a Maven/Gradle library directly, or download the fat JAR from the release assets, without building from source. This allows other projects to build on / extend SPRUCE more easily.
CUR sanitizer script
A new cur_sanitize.py script strips or redacts sensitive columns from CUR files (account IDs, tags, cost categories, resource IDs) before sharing them for debugging or support. This makes it easier to provide reproducible test data without exposing sensitive information.
Simplified Docker usage
The SPRUCE Docker image now declares an ENTRYPOINT, removing the need to specify the fully-qualified class name and other configuration on the command line.
The docker run invocation is simpler:
docker run ghcr.io/digitalpebble/spruce:1.0 -i <inputCUR> -o <enrichedCUR>
but can still be overridden if necessary.
Bug fixes
- Spark 4.x compatibility. A
ClassCastExceptionwhen readingMapTypeproduct columns on Spark 4.x has been fixed. - BoaviztAPI energy source. The module now reads the final energy figure directly from the API response instead of recalculating it locally, avoiding discrepancies with the upstream methodology.
- Water module. Water consumption data (
wcf.csv,water-stress.csv) is now independent of ElectricityMaps region codes, using SPRUCE’s own mapping from Cloud Infrastructure Map (see above). This yields more accurate results.
Getting started
See the documentation site to get started. You are only a few minutes away from understanding the environmental impact of your cloud usage better.